PureData Compiler
9/30/2019|Dylan BuratiThis post is about a tool I created for writing PureData patches as Python programs. The current version is on Github and PyPI (supports Python 3.5 and later).
Background
In late March 2019, I began writing an audio app for Android, similar to GarageBand on iOS. The purpose of the app is to create and play instruments based on samples - short audio clips that the user can map to different keys on a virtual keyboard. I chose PureData as the audio library after several Google searches, and with the help of the excellent pd-tutorial.com, used the built-in GUI to write a patch to read a .wav file and play it back.
Terminology
- Patch: a program that the user writes graphically, which PureData runs
- patches generally run until they are force closed, generating audio in response to user input
- Object: a "node" in the patch, which performs some operation based on its
type and content
- different object types are represented as different shapes
- the most common types have a user-defined string as their content
- Inlet: the input slot(s) on the top of an object
- Outlet: the output slot(s) on the bottom of an object
- Connection (wire): an "edge" in the patch, which must start at an outlet
and end at an inlet. These visually represent the data flow of the program.
- Inlets and outlets can have multiple connections each
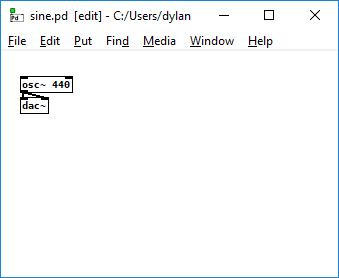 Example Patch: plays a sine wave at 440 Hz on both stereo channels
Example Patch: plays a sine wave at 440 Hz on both stereo channels
Compiler Attempt 1
I built on my first patch to add a pitch parameter, but I did not make much progress, since every change required a mouse action. I decided I would be more productive using a text-based language for PureData. I found the .pd file format docs here and wrote the first draft of my compiler.
I ended up with a 550 line program, with the "source" to compile from in a long multiline string at the top. The following is an excerpt:
from typing import *
import re
sample = '''
def reactive_expr2
obj reactor{local} = "trigger bang float" ({2})
obj {3} = "{0}" ({1} reactor{local}$1, reactor{local}$2)
end
array array1 = "array1" ()
obj panel = "receive sample_file" ()
msg reader = "read -resize \$1 array1" (panel$1)
obj soundfiler = "soundfiler" (reader$1)
floatatom lenSamples = "" (soundfiler$1)
# ... playback array1
'''
# ... regex parsing utilities
def compile(s_commented, filename, subpatches=None, include_canvas=True):
s = '\n'.join([read_to_delimiter(commented_line, 0, '#')[0] for commented_line in s_commented.splitlines()])
start_idx = 0
base_x = 25
base_y = 25
current_x = base_x
current_y = base_y
line_step = 0 # type=0 identifier=1 text=2 wiring=3 funcdef=10 funccall=20 error=-1
if subpatches is None:
subpatches = {}
lines = []
connections = []
functions = {}
pending_connections = {}
current_fn = None
while start_idx >= 0:
if line_step == 0:
# parse stuff, increase start_idx,
# do stuff, update line_step, repeat
elif line_step == 1:
# ...
Attempt 2
After I had worked with my hacked-together version for a while, I identified some pros and cons.
- + things can have variable names
- − commas and dollar signs need to be escaped manually
- − no autocomplete or syntax highlighting
- − the parser is a giant switch statement
- − no support for loops, which would be helpful to create many similar objects
- −
the parser assumes each object constructor takes one string and a list of connections
floatatomignores the string -arrayconverts the string to a positive integer
With the last two, I realized that I should have written the compiler as a Python library, and more importantly I should have designed it so that people could actually use it.
In the second version, I moved the task of building a patch into a class, which
keeps track of each element's content, position and size. The different types of
PureData objects also became classes, which are constructed with only the data
they need. Python's ability to overload indexers via __getitem__ made it
easy to refer to outlets as integer-keyed properties of their owner objects.
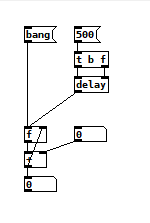
Example Usage
from puredata_compiler import Patch, write_file
def example():
"""Patch that increments a counter"""
patch = Patch()
obj, msg, floatatom, connect = patch.get_creators('obj, msg, floatatom, connect')
bang = msg('bang')
delay_params = msg('500', new_row=0, new_col=1)
delay_trig = obj('t b f', delay_params[0])
delay = obj('delay', delay_trig[0], delay_trig[1])
start_val = obj('f', (bang[0], delay[0]), x_pos=25, y_pos=125)
increment = floatatom(new_row=0)
current_val = obj('+', start_val[0], increment[0])
# connect is different - it takes an existing element and adds connections,
# so you can create circular structures
connect(start_val, (), current_val[0])
current_val_display = floatatom(current_val[0])
return patch
if __name__ == "__main__":
pd_example = example()
write_file('pd_example.pd', str(pd_example))
Result
Future improvements
This is the first Python project that I've written using type hints, and I was impressed by their descriptive power. The type checker caught many of my errors right away, and writing the signatures and docstrings for each function forced me to think about possible design issues.
Since having a type system was so beneficial in writing this compiler, I think it would be nice to implement one for PureData, which often generates type errors like "signal outlet connected to nonsignal inlet". This would be difficult though, because the number of inlets or outlets an object has can change based on its text content.
Support for more complex PureData elements could be added fairly easily - I only
included the bare minimum because my Android app works with
libpd, and the patch is never seen
by users.